
[운영체제(OS)] 페이징(Paging), Fragmentation(단편화), TLB 란?
resilient
·2022. 2. 17. 13:23
저번 시간까지는 메모리 관리를 어떻게 하는지, contiguous allocation이 무엇인지, MMU가 무엇인지에 대해서 살펴봤습니다.
혹시 이 세가지 개념에 대해 모르시거나 헷갈리시는 분들은 저번 게시물을 참고해 주세요!
[운영체제(OS)] 메모리관리 - 주소바인딩, Contiguous allocation 그리고 MMU 란?
지난 시간까지 살펴봤던 멀티프로그래밍에서는 다른 프로세스/쓰레드 끼리 통신을 하게 되고 공유자원을 사용하다 보니 문제점도 많았고 그에 대한 해결책을 살펴봤었습니다. 이번 시간부터는
resilient-923.tistory.com
0. Fragmentation이란?
먼저 저번시간에 배운걸 간단히 복습해보겠습니다.
contiguous allocation을 하면 일단 MMU가 굉장히 간단해진다는 장점이 있었습니다. 더하기 + 상한선 체크만 해주면 되기 때문이죠.
하지만 저번에도 잠깐 언급했듯이, 현재 시스템에서는 사용되지 않는데요, 안 쓰는 이유를 오늘 한번 알아보겠습니다.
contiguous allocation(연속적 할당) 의 단점
우리가 사용하는 컴퓨터는 프로세스가 한번에 여러 개가 실행이 됩니다. 프로세스들 각각의 크기와 작업 수행 시간 등이 물론 다 다르겠죠?
그림과 함께 살펴보겠습니다.
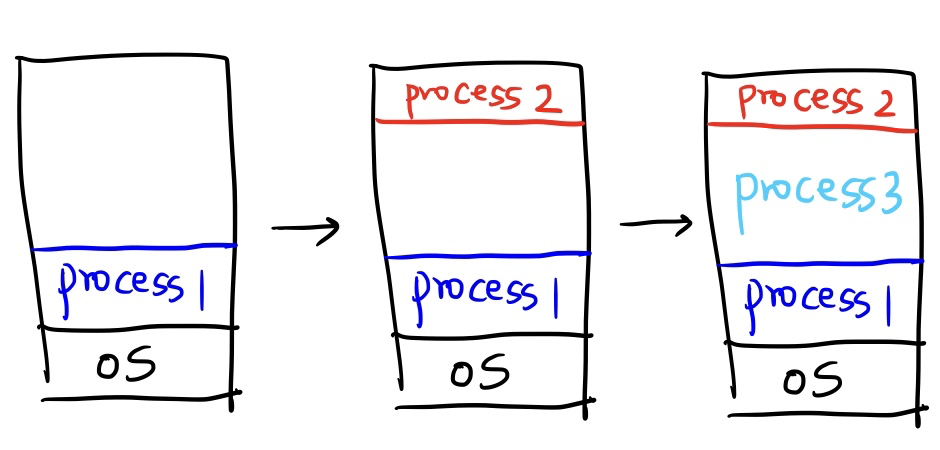
먼저 process1을 실행시켰습니다. 앞으로 실행되는 프로세스들은 연속적으로 배치될겁니다.
contiguous allocation이라는 게 logically contiguous 이면 physically contiguous라고 저번 시간에 배웠으니까요! 즉 Process1을 쪼개서 비어있는 메모리에 넣는다던지 쪼개서 순서를 바꾼다던지의 행위는 일어날 수 없습니다. 연속적으로 놔야 하는 것이죠.
위 사진은 Process1, Process2, Process3이 비어있는 메모리에 연속적으로 배치가 되는 모습입니다. 맨 마지막에 Process이 들어오면서 메모리가 꽉 찼네요!
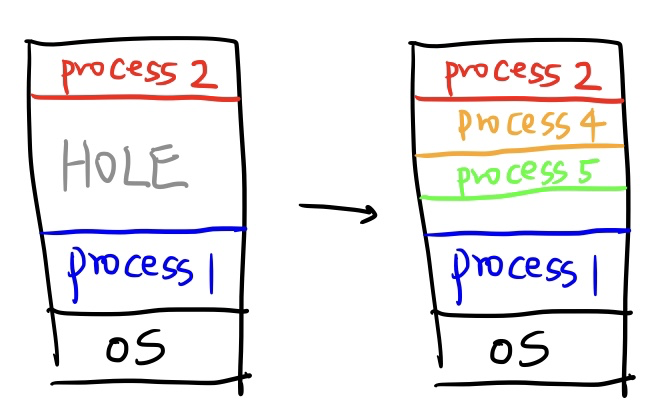
이제 Process3이 종료되었습니다. 그러면 Process3이 있던 자리에 메모리 공간이 비게 되는데요, 이 공간을 HOLE이라고 합니다.
HOLE에 Process4, Process5가 들어왔네요. 비어있는 메모리 공간에 딱딱 맞춰서 실행이 되면 참 좋겠는데 말이죠.. 현실은 이렇지 않습니다.

Process5까지 들어가면서 약간의 메모리 공간이 비어있지만 Process6이 실행되는데 필요한 메모리 공간은 없군요. Process1 이 끝나면 공간이 생기겠지만 나머지 Process들은 끝나도 2,4,5가 한 번에 끝나지 않는 이상 공간이 부족할 것 같습니다.
Fragmentationd은 Internal Fragmentation(내부 단편화)과 External Fragmentation(외부 단편화)로 나뉘는데요,
이것이 바로 External Fragmentation(외부 단편화) 문제입니다. Fragmentationd은 단편화라는 뜻 말고도 조각이라는 뜻이 있는데요, 메모리가 남아있는 데 사용하지 못하고 조각조각으로 나뉜다 해서 붙여진 이름입니다.
자, 정리해보면 메모리가 할당되고 해제되는 작업이 반복될 때 메모리 중간중간 사용하지 않는 빈 메모리 조각들이 많이 생겨버려서 총 메모리 공간은 충분하지만 실제로 Process 실행을 위해 할당해줄 수 있는 메모리 공간이 없는 문제를 External Fragmentation이라고 하는 것이죠.
1. Compaction이란?
자, 그럼 위 문제를 어떻게 해결을 했을까요? 쉽게 생각해보면 실행되어야 할 Process가 필요한 메모리 공간만큼 사용 중인 메모리 공간들을 정리해서 자리를 만들어주면 됩니다. 그림으로 살펴보면 아래와 같습니다.

Process2와 Process4를 옮기고, Process6에 필요한 메모리 공간을 만들어주는 것이죠.
하지만 이 방법은 Process2,4를 옮길 때 임시로 복사했다가 다시 가져오는 방식을 사용합니다. 즉 다른 저장소 하나가 더 필요하다는 것인데요, 지금은 SSD이지만 SSD가 없을 때는 HDD를 사용했을 텐데 속도가 굉장히 느리죠.
정리하자면 Compaction이란 비어있는 메모리 공간을 연속적인 공간으로 만드는 과정이라고 할 수 있습니다.
Compaction은 External Fragmentation을 줄일 수 있는 방법이 될 수 있긴 하지만 메모리를 복사하고 다시 가져오는 과정인 I/O Problem이 생기게 됩니다. 이과 정에서 오버헤드가 발생할 가능성이 아주 크죠. 따라서 더욱 좋은 방법을 찾아야만 했는데요. 이 고민이 Paging(페이징 기법)을 만들게 되는 것이죠.
위의 방법도 가장 효율적인 방법으로 사용하기 위해 많은 노력을 했습니다. 예를 들어 그림 4에서 Process6을 어떻게 넣는 게 효율적일까? 어떻게 fit 하게 딱 맞게 넣을까? 를 고민했고, first-fit(최초 적합), best-fit(최고적합), worst-fit(최악적합) 세가지 개념이 탄생하게 됐죠.
2. first-fit(최초적합), best-fit(최고적합), worst-fit(최악적합)

first-fit(최초적합) : 메모리를 할당해줄 때 hole을 찾기 위해 순차적으로 앞에서부터 탐색을 합니다. 탐색을 하다가 hole이 발견되면 최초에 발견된 hole에 넣는 방법입니다.
best-fit(최고 적합) : 여기저기 다 대입시켜보고 가장 크기가 잘 맞는 hole에 배치하는 방법입니다.
worst-fit(최악 적합) : 남은 hole들 중 가장 큰 hole에 배치하는 방법입니다. 이렇게 하면 남은 hole의 크기가 클 테니, 다른 프로세스가 또 사용할 수 있게 하는 방법이죠.
위에서 설명했던 방법들은 프로세스 크기별로 메모리를 할당합니다. 이를 가변 분할이라고 하죠. 모든 프로세스 크기가 동일한 게 아니기 때문입니다. 이 말은, 어떻게 집어넣든 프로세스 크기가 각각 다르기 때문에 External Fragmentation 문제를 막을 수 없다는 것이죠.
그래서 나온 게 Paging입니다. Paging은 메모리를 고정된 크기들로 분할시켜서 할당시키는데요, 이 방법을 고정 분할이라고 부릅니다. 위에서 언급했듯이, External Fragmentation은 가변 분할로 인해 발생하는데요, Internal Fragmentation은 고정 분할로 인해 발생하게 됩니다. 이제 Paging에 대해서 자세히 알아보겠습니다.
3. Paging
1. pages: 논리 메모리(Logical Memory)를 일정한 사이즈로 분할한 블록
2. frames: 물리 메모리(Physical Memory)를 일정한 사이즈로 분할한 블록먼저 프로세스의 논리적 주소 공간을 여러 개로 쪼갠 것이 페이지(Page)라고 하고, 물리적 주소 공간을 여러 개의 크기로 쪼갠 것을 프레임(Frame)이라고 합니다. 페이지와 프레임은 모두 동일한 사이즈로 쪼개야 하죠.
페이징 기법은 쪼개진 페이지와 프레임을 매핑시켜줍니다. 아래 그림으로 보겠습니다.
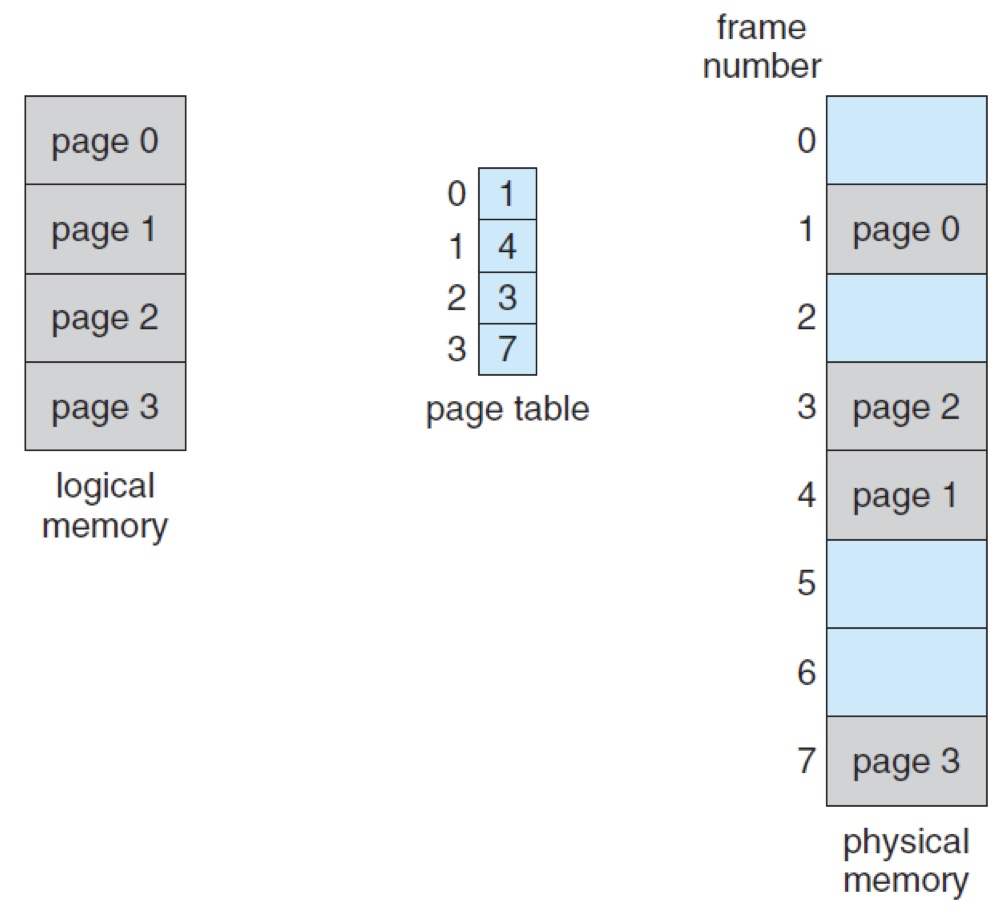
위 그림에서 왼쪽은 논리적 메모리 주소, 오른쪽은 물리적 메모리 주소입니다. 그림에서 볼 수 있듯이 모두 같은 크기로 쪼개져있죠.
여기서 논리적 메모리 특정 주소 값은 페이지1의 첫 번째 Offset 으로 표현 가능하고, 물리적 특정 주소값 또한 프레임1의 첫번째 Offset으로 표현이 가능합니다.
여기서 Offset이란 객체 안에서 객체의 처음부터 주어진 인덱스라고 생각하시면 됩니다. 메모리에서는 두 번째 주소를 만들기 위해 기준이 되는 첫번째 주소에 더해진 값이라고 하네요. 예를 들어 객체 A에 문자열 abcdef가 있다고 할 때, c는 A의 시작점에서 2의 오프셋을 지닌다고 할 수 있죠.
4. Internal Fragmentation
자 이제 고정 분할의 문제점이 Internal Fragmentation에 대해서 알아보겠습니다.
동일한 크기로 잘랐고, 연속적으로 배치하지 않아도 되기 때문에 External Fragmentation 은 이제 발생하지 않죠. 그렇다면 이제 메 모리리에 비어있는 hole 없이 할당받을 수 있을까요?
동일한 크기로 자를 때, Page크기에 맞게 딱 나눠 떨어지지 않을 가능성이 존재합니다. 한 블록의 크기보다 약간 더 큰 메모리 크기를 가지고 있다면 남는 공간이 생기겠죠. 이러한 경우를 Internal Fragmentation(내부 단편화)라고 합니다.
4-1. 그럼 페이지를 프레임에 어떻게 매핑하는 걸까요?
먼저 페이지 테이블(Page table)을 알아야 하는데요, 페이지가 각각 매핑될 프레임에 대한 정보가 기록된 테이블을 페이지 테이블이라고 합니다. 즉, 페이지 테이블은 페이지의 수만큼 엔트리를 가지게 됩니다.
예를 들어 시스템이 1024KB(=1024 * 1024byte)의 물리적 주소 공간을 갖고, 각 페이지는 1024byte의 공간을 가지고 있다고 가정해보겠습니다. 페이지와 프레임의 사이즈는 동일해야 하므로 현재 물리적 공간에 페이지도 총 1024개가 존재하게 되는 것이죠.
그럼 하나의 페이지 내에서 가질 수 있는 offset의 주소는 0부터 1023이 되고 프레임 역시 같은 사이즈이므로 0부터 1023까지의 offset이 존재하게 됩니다. offset의 정보는 그대로 넘어가게 됩니다.
4-2. 그럼 페이지 테이블에는 어떤 데이터들이 담겨있을까요?
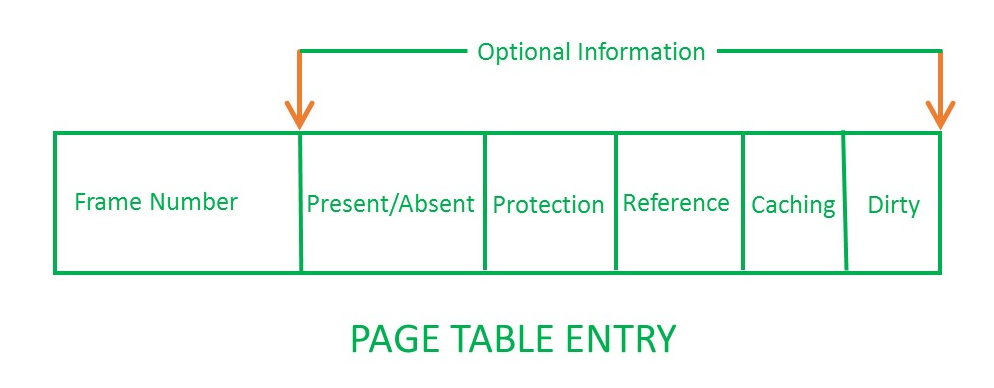
다음과 같은 부가적인 데이터들이 들어가 있습니다.
- reference bit (accessed bit) : 해당 페이지가 참조된 적이 있는지 판단하는 정보를 담고 있습니다.
- valid bit (present bit) : 현재 페이지가 물리 메모리에 있는지, 페이징 파일에 있는지 여부에 대한 정보를 담고 있습니다.
- dirty bit (modified bit) : 현재 페이지가 수정이 된 적이 있는지에 대한 정보를 담고 있습니다.
지금까지 내용으로 보면, 페이지 테이블은 각각의 프로세스마다 존재하게 되고 각 페이지 테이블은 프로세스가 가지고 있는 페이지 수만큼의 엔트리를 가지게 됩니다. 각각의 엔트리에는 부가적인 데이터를 포함해서 매핑되는 프레임의 정보들을 가지고 있죠.
그렇다면 페이지 테이블의 문제점은 뭐가 있을까요?
5. Large Page Table Problem(페이지 테이블의 크기 문제)
먼저 프로세스마다 페이지 테이블이 존재하게 된다고 했는데요, 프로세스 최대 크기를 기준으로 생각해보겠습니다.
예를 들어 2^32bit의 논리적 메모리가 존재하고 각 페이지 사이즈는 2^12bit, 페이지 테이블에서 하나의 엔트리의 크기는 4byte라고 해볼까요? 그러면 프로세스의 페이지 테이블은 약 2^20개의 페이지 엔트리를 들고 있어야 합니다.
페이지 엔트리의 개당 크기가 4 bytes면 는 2^20 * 4bytes = 4 Mbytes 정도가 되죠. 컴퓨터에서 돌아가는 프로세스의 수가 10개라고 가정해보면 벌써 페이지 테이블 크기만 40MB가 되죠. 딱 봐도 성능 문제가 있어 보입니다.
그럼 이 문제들을 어떻게 해결할까요?
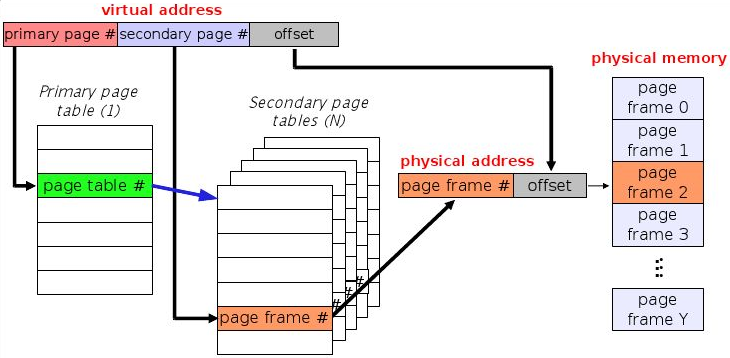
5-1. Multi-level Paging
멀티 레벨 페이징 기법은 페이지 테이블 자체가 다시 페이징 되는 것입니다. 예를 들어, 일반적인 페이징 기법은 1000페이지 중 38페이지 1번째 줄에 데이터가 있어라는 식으로 페이지 테이블을 작성합니다.
여기 멀티 레벨 페이징 기법을 적용하면 3번째 챕터 안에 두 번째 페이지에 1번째 줄에 데이터가 있어라고 알려주는 것이죠. 이 예시는 챕터라는 레이어가 하나 추가되었으니 두 단계 페이징을 적용한 것이겠죠?
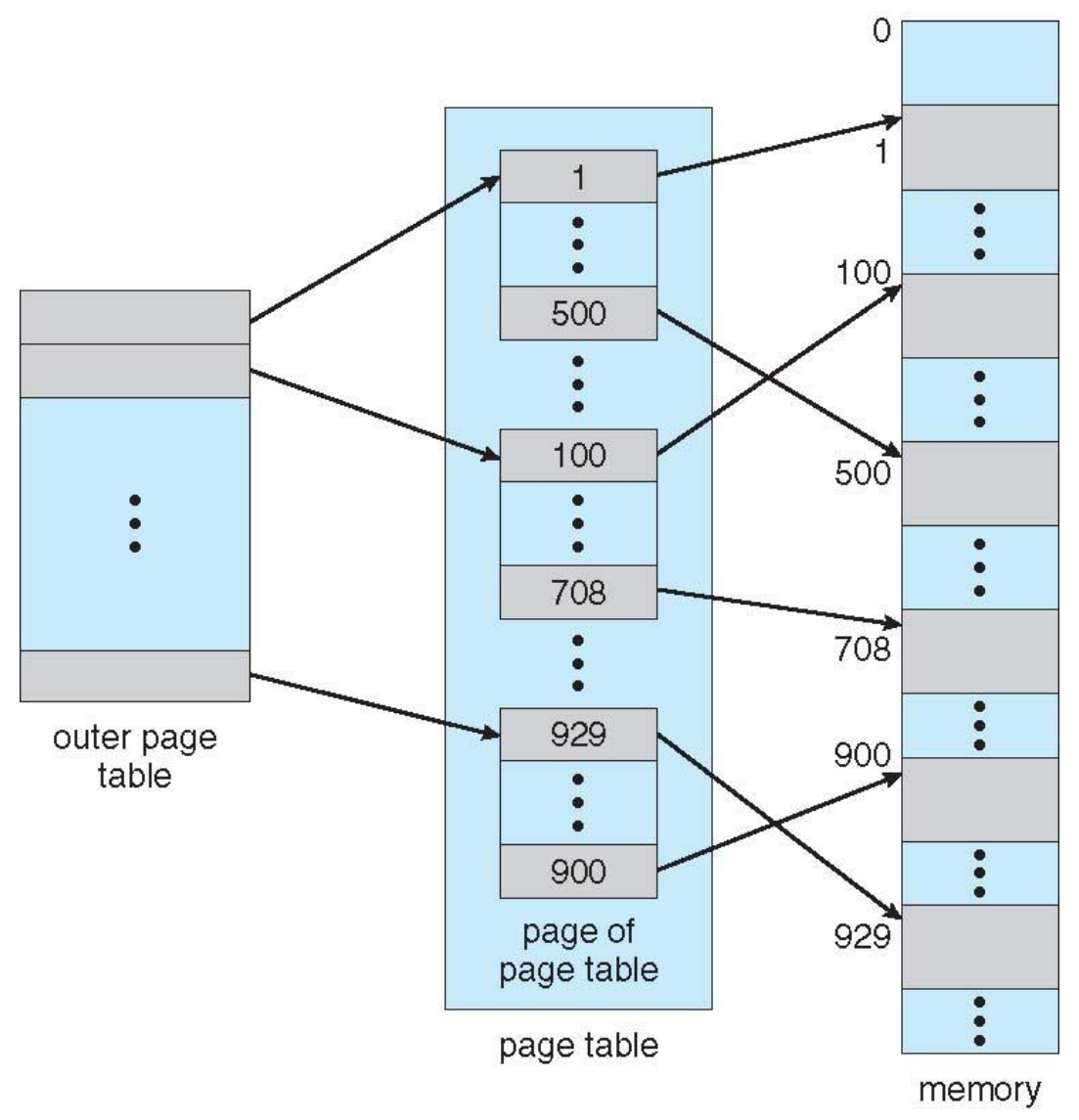
멀티 레벨 페이징 기법은 모든 페이지 테이블을 들고 다니지 않아도 되기 때문에 메모리 이슈가 덜해지지만, Chapter -> page -> offset 순으로 접근을 해야 하기 때문에 레이어가 많아진다고 가정했을 때 메모리 접근에 대한 오버헤드 이슈가 생길 가능성이 있습니다.
5-2. Hashed Page Table
주소 공간이 32bit보다 크면 해시 값이 가상 페이지 번호가 되는 해시형 페이지 테이블을 많이 사용합니다. 해시형 테이블의 각 항목은 연결 리스트를 가지고 있고, 해시 원소는 세 개의 필드(가상 페이지 번호, 매핑 페이지 프레임 번호, 연결 리스트 상의 다음 포인터)를 가지고 있죠.
논리적 주소 공간의 페이지 번호인 p를 해시한 결괏값으로 테이블을 검사한 뒤, 해당 물리적 메모리를 찾아가게 됩니다. 같은 해시값으로 리스트 하나를 이용할 수 있기 때문에 문제를 해결할 수 있습니다.
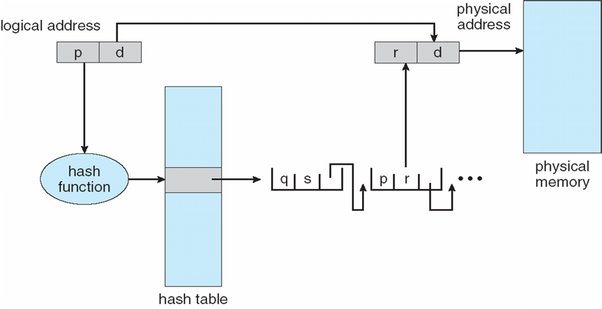
5-3. Inverted Page Table
Inverted Page Table 은 물리적 메모리 주소 입장에서 만들어진 테이블 구조입니다. 이전까지의 테이블은 모두 논리적 주소 공간을 기준으로 테이블을 만들고 나누어진 페이지의 순서대로 페이지 테이블에 매핑하는 구조였죠.
따라서 이전에는 페이지 테이블에 몇 번째 프레임인지에 대한 정보를 담았다면, 이제는 프로세스 번호의 pid값도 담고 있습니다.
Inverted Page Table은 프로세스마다 하나의 페이지 테이블이 만들어지는 것이 아니라 전체 테이블만 있으면 되는 장점이 있지만 그만큼 크기가 크기 때문에 검색할 때 시간이 더 소요됩니다. 또한 pid 정보가 없으면 원래 페이지 테이블로 가서 업데이트를 하고 수정을 해야 한다는 번거로움이 있죠.
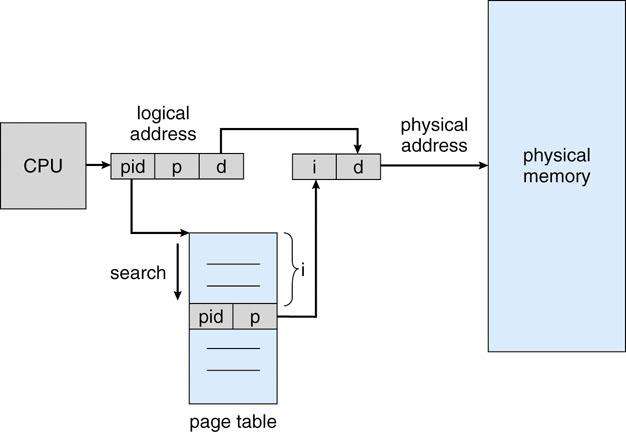
6. Memory Access Overhead Problem(페이지 테이블의 속도 문제)
페이지 테이블을 어디에 저장해야 가장 빠르게 참조하고 주소 변환을 시킬 수 있을까요?
당연히 저번 시간에 배웠던 MMU겠죠? 하지만 4MB의 메모리를 MMU에 넣는 건 말이 안 됩니다. 결국 CPU가 아닌 램에 저장을 해야 한다는 것인데... 이렇게 되면 메모리에 1번 접근하기 위해서 메모리를 2번 접근해야 합니다. 페이지 테이블에 접근해서 매핑된 프레임의 정보를 읽고 난 뒤, 실제 메모리에 접근해서 데이터를 읽어와야 하는 것이죠. 이 과정에서 오버헤드가 발생하고요. 어떻게 해결할까요?
바로 캐시 메모리를 쓰는 것입니다. 페이지 테이블의 크기가 커도 실제로 다 쓰이는 건 아니기 때문에 이 점을 이용하는 것이죠. 프로그램은 locality라는 특성을 가지고 있어서 자주 쓰이는 녀석은 자주 쓰이고 안 쓰이는 녀석은 거의 안 쓰이게 됩니다. 이 특성을 가져와서 실제로 참조되는 페이지는 이 중에 몇 개 되지 않는다 라는 원리를 이용한 것이죠.
TLB(Translation Look-aside Buffer)
이렇게 나온 방법이 Associative Memory인 TLB(Translation Look-aside Buffer)를 이용하는 것인데요. 일반 메모리는 주소에 접근해서 데이터를 반환하지만 Associative Memory는 인덱스를 이용해 매핑된 데이터를 저장해 두고, 다음에 동일한 접근일 때는 해당 데이터를 빠르게 반환할 수 있게 하는 것이죠. 이러한 점들이 캐시와 동일한 개념이라고 할 수 있습니다.
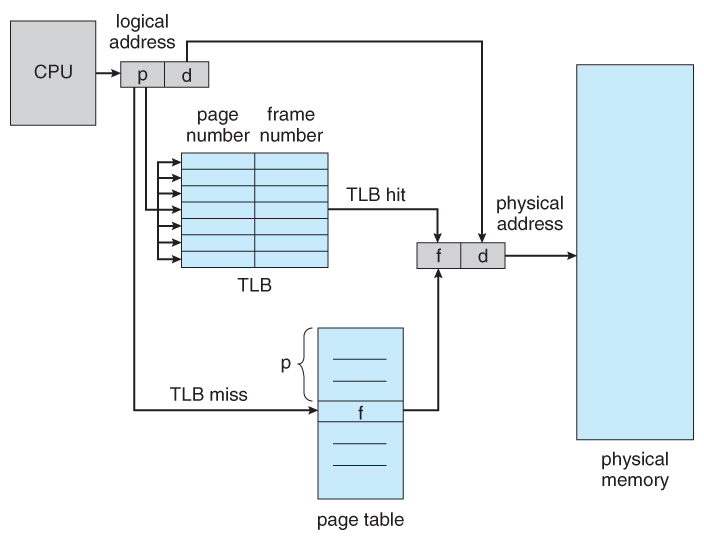
그런데 위처럼 TLB를 사용해서 프레임에 대한 매핑 정보를 빨리 알아보려고 했는데 TLB 테이블에 아직 프레임의 번호가 없으면 다시 페이지 테이블을 찾아가서 프레임 번호를 얻고, 이 녀석을 TLB에 저장해줘야 합니다. TLB의 크기는 정해져 있기 때문에 모든 프레임 번호에 대한 데이터를 다 저장하고 있을 수 없기 때문이죠.
7. 정리
이번 시간에는 Fragmentation에 대해서 자세히 알아봤고, 페이징 기법을 통한 메모리 관리에 대해 공부했는데요. 너무 많은 내용이 한 번에 들어와서 헷갈릴 수도 있지만 천천히 읽어보면 크게 논리적 주소 공간과 물리적 주소 공간을 동일하게 쪼개서 비연속적으로 고정 분할을 시켜주고 각각 매핑해주는 기법이라고 생각하시면 될 것 같습니다.
다음 게시물에서는 세그멘테이션(Segmentation)을 통한 메모리 관리 기법에 대해 공부해보려고 합니다.
감사합니다.
Reference
'CS & Network > 운영체제(OS) & 컴퓨터구조' 카테고리의 다른 글
| [운영체제(OS)] 스와핑(swapping), 가상메모리(virtual memory) 란? (8) | 2022.03.03 |
|---|---|
| [운영체제(OS)] 페이징(Paging), 세그멘테이션(Segmentation) 이란? (0) | 2022.02.28 |
| [운영체제(OS)] 메모리관리 - 주소바인딩, Contiguous allocation 그리고 MMU 란? (3) | 2022.01.22 |
| [운영체제(OS)] 데드락(DeadLock), 교착상태 해결방법 -2 (0) | 2022.01.16 |
| [운영체제(OS)] 데드락(DeadLock), 교착상태 란? - 1 (0) | 2022.01.14 |





